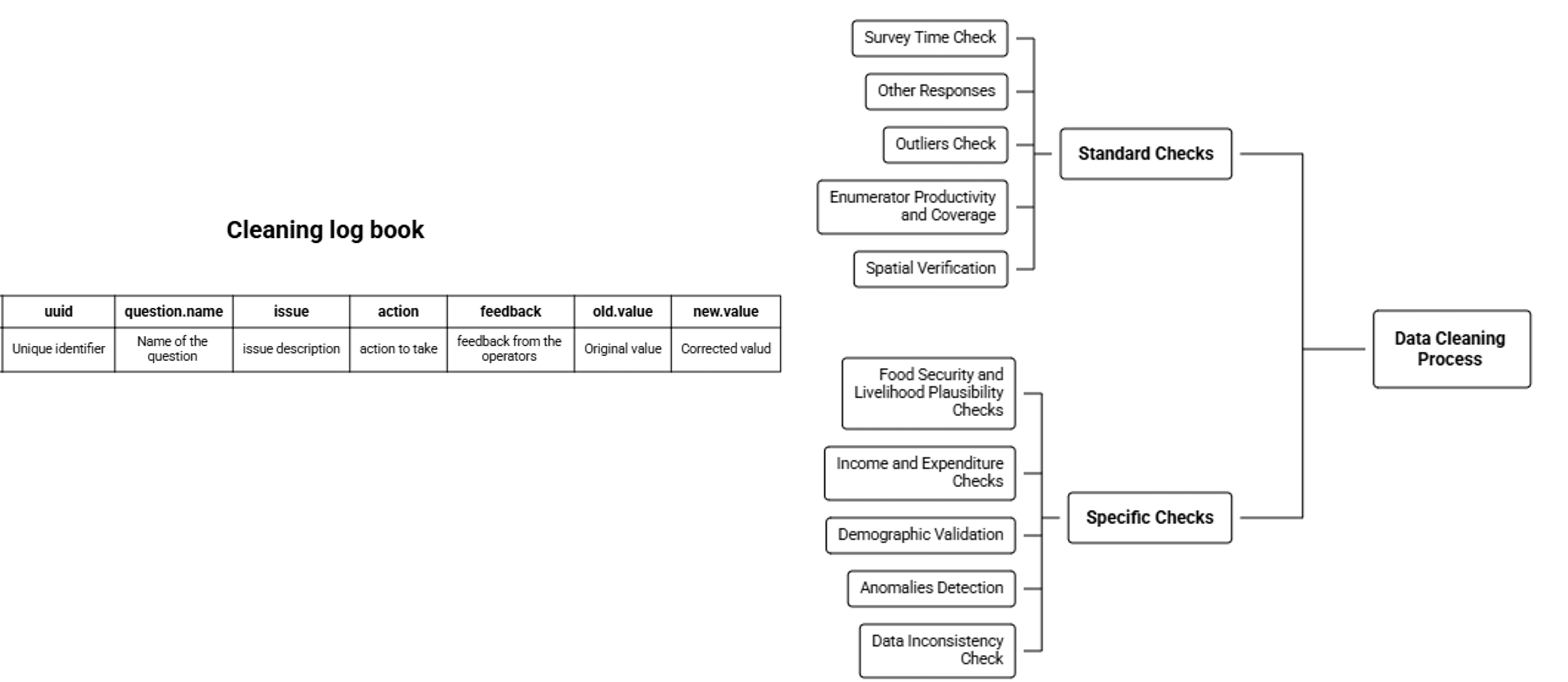
Data Cleaning Process
R programming
Data Cleaning
Introduction
Data cleaning is the process of identifying and correcting errors and inconsistencies in raw data to improve data quality 1. in the humanitarian context identifying data errors will be categorized into two steps. standard checks and specific checks. depending on the scope of data collection points, all data should pass under the standard checks. while specific checks will depend on the availability of indicators and data collection points.
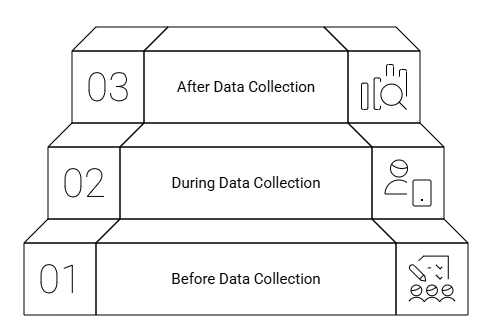
The data cleaning process is not one time task, it should start from from the planning stage by including constrains and validation measures in the data collection tools to mitigate some of the potential data errors. also during data collection we’ll need to run high-frequency-checks to identify data errors and communicate with the team for making corrective actions and at the end of data collection we’ll run in-depth checks and amend the changes to generate clean data.
Somalia Case Study
The Planning, Monitoring, Learning, and Evaluation (PMLE) unit has implemented a standardized data cleaning procedure to maintain data quality and consistency. This process ensures that all data from process monitoring and assessments meet the World Food Programme’s quality standards. Similar to accounting practices, every modification or adjustment made to the data is meticulously recorded. This methodical tracking helps in identifying and addressing any discrepancies or errors in the data effectively.
Footnotes
IMB definition of Data Cleaning↩︎